· 3 min read
A medical embedding model that beats OpenAI 7x on note recall
How we fine-tuned EmbeddingGemma-300m on MIMIC-III clinical notes to predict disease at AUROC 0.934, outperforming OpenAI embeddings 7x on next-note recall.
San Francisco, California — Our new medical EmbeddingGemma-300m fine-tuned on medical data can predict diseases from patient notes with an AUROC of 0.934 and provide increased survival analysis.
The problem with embedding models
The current problem with embedding models is that they are trained to match text content, but text covers a whole range of information, from language to style, to semantics, to the underlying information or instructions. When it comes to needing embeddings which contain the specific information and are agnostic to stylistic information, off-the-shelf embeddings typically fail.
For the medical context this is critical, as we need to be able to faithfully extract the correct clinical information and prioritise this over other stylistic information.
Fine-tuning our own embedding model for clinical utility
We built the first generation of an internal embedding model by fine-tuning the EmbeddingGemma-300m using the MIMIC-III dataset, which is a large, freely available critical care database containing de-identified health records from over 40,000 ICU patients between 2001 and 2012. Using the contrastive loss, we fine-tune the embedding model by setting the anchor to be a patient note at time t and the positive to be a patient note at t + 1. This forces the model to match notes based on the medical context and not to rely on the style of writing, which is typically consistent between notes.
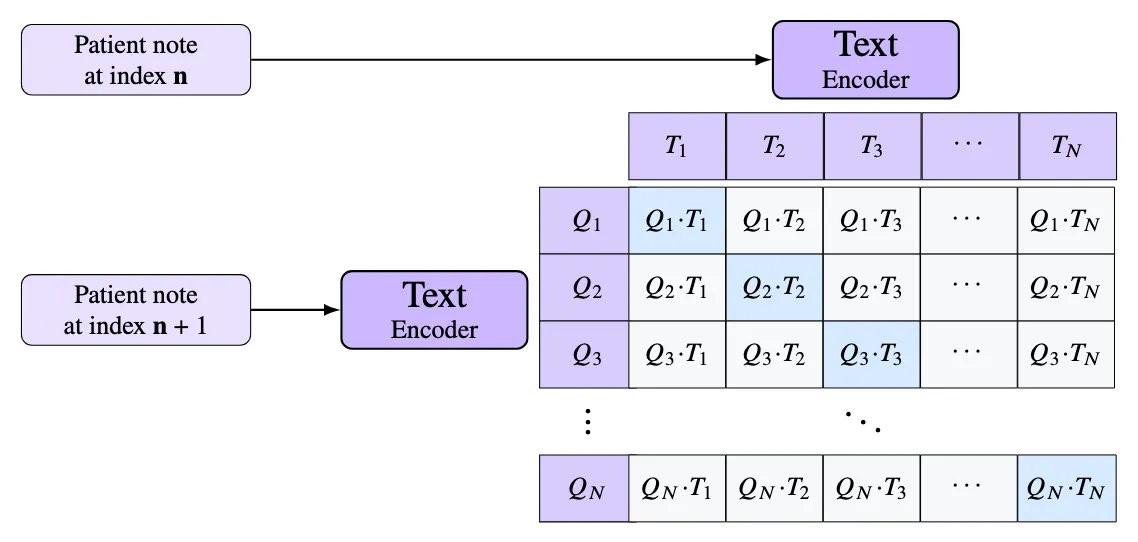
Fine-tuning a model this way yields surprisingly powerful results. Given a recall task of recalling the next patient note, our model is able to achieve a top-5 accuracy of 65%, far surpassing the accuracy of the base model and OpenAI embeddings, which achieve 6% and 9% respectively.
This isn’t surprising as we’re optimising for this in the loss, but where this gets exciting is that these representations make for much better medical performance on downstream tasks. Our model beats the base model and OpenAI when trying to predict diagnosis (ours: 0.934, OpenAI: 0.809, base: 0.674 AUROC), and when performing survival analysis (ours: 0.70, OpenAI: 0.67, base: 0.59 C-Index).
We can clearly see why the model is so powerful at producing these results when we create UMAP plots and color code by common disease type. Compared against the off-the-shelf base model and OpenAI embeddings, our trained model produces visibly tighter clusters per diagnosis:
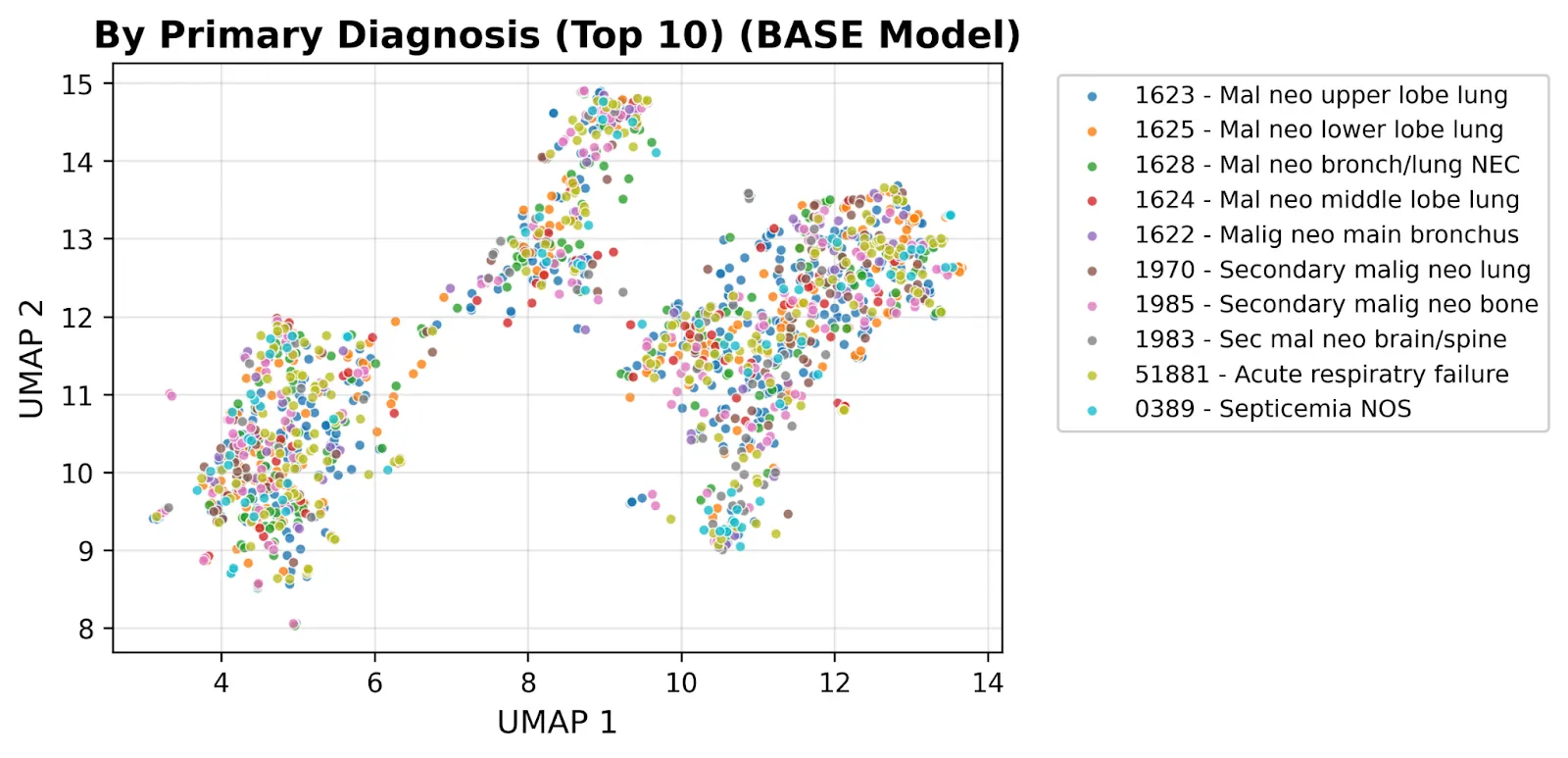
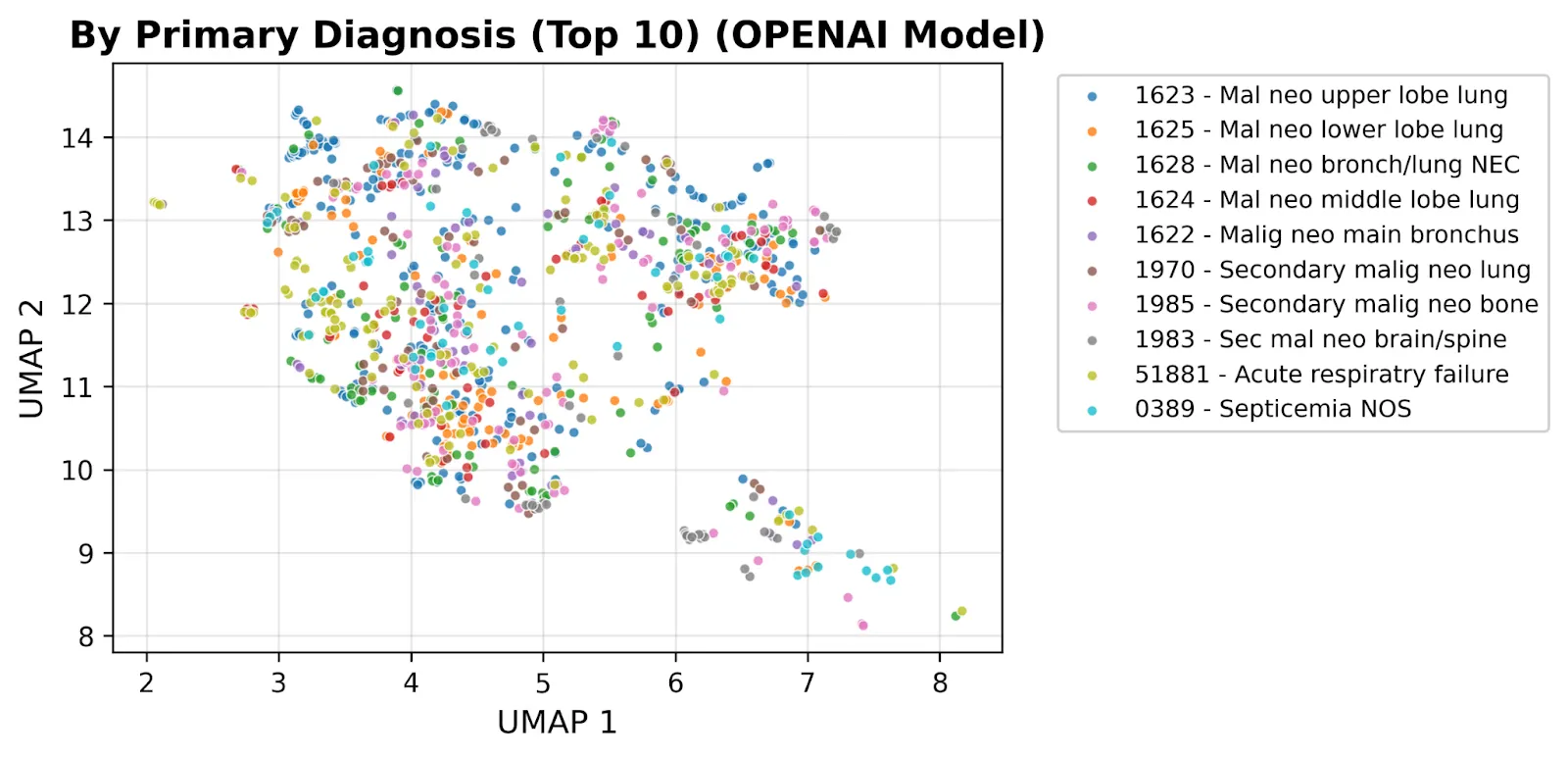
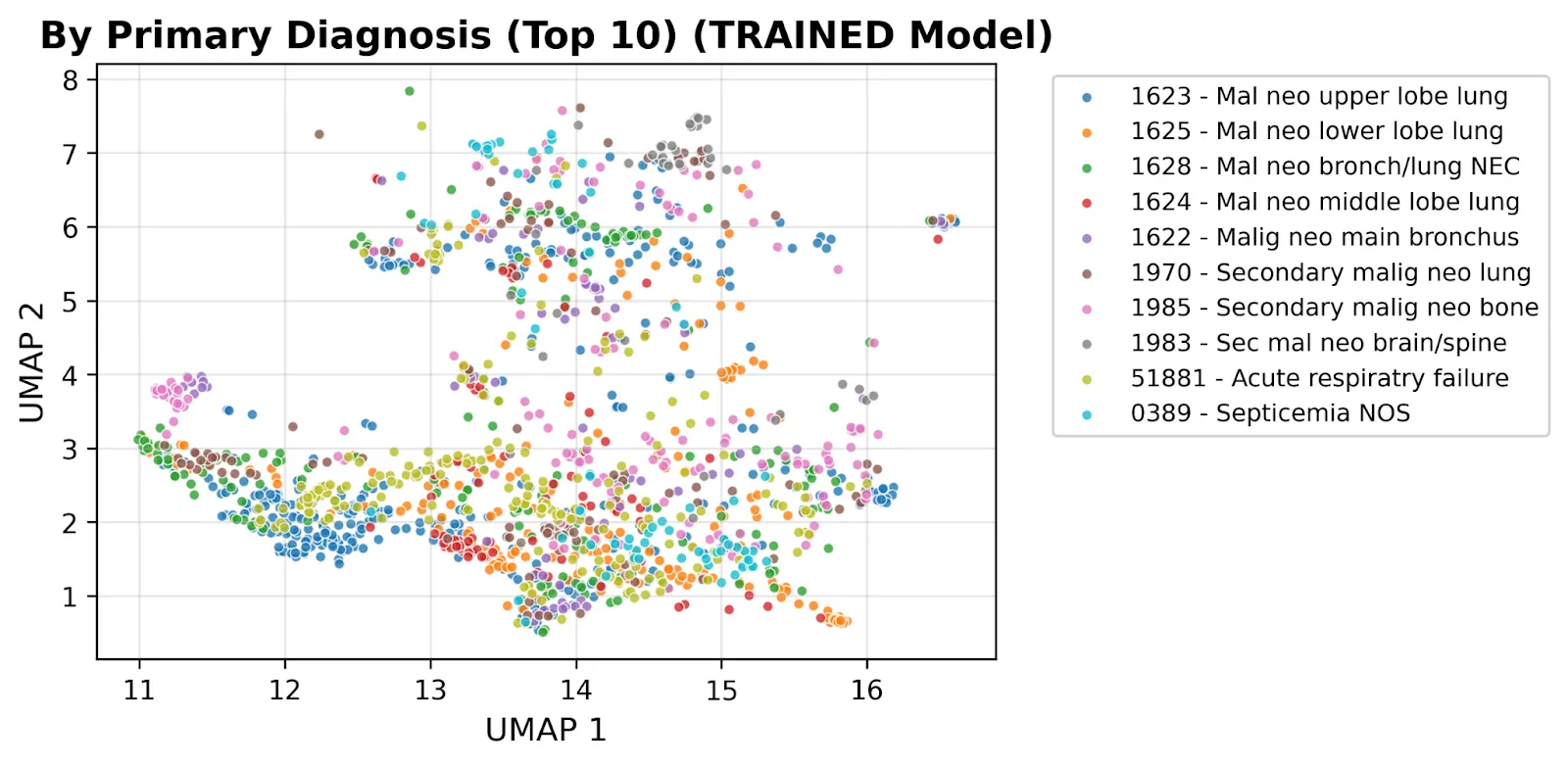
The contrast tells the story: the same clinical notes, the same diagnoses, but a clinically meaningful geometry emerges only after fine-tuning. This is the foundation we’re building toward Aesclea, our long-range temporal model of oncology patients, and the same medical-knowledge stack that lets our patient-report platform score 100% on the US Medical Licensing Exam. See how it works end-to-end for the patient-facing product.
If you’re working on medical AI and want to compare notes (or use these representations on a real downstream task), reach out.